Word2vec
1. 背景
为了加快训练的速度,并且使得词向量更加表现出词语甚至是短语之间在语言和语法上的关联关系,作者在bengio06 NNLM
前馈神经网络的基础上提出了CBOW和Skip-gram的模型,如下图所示:
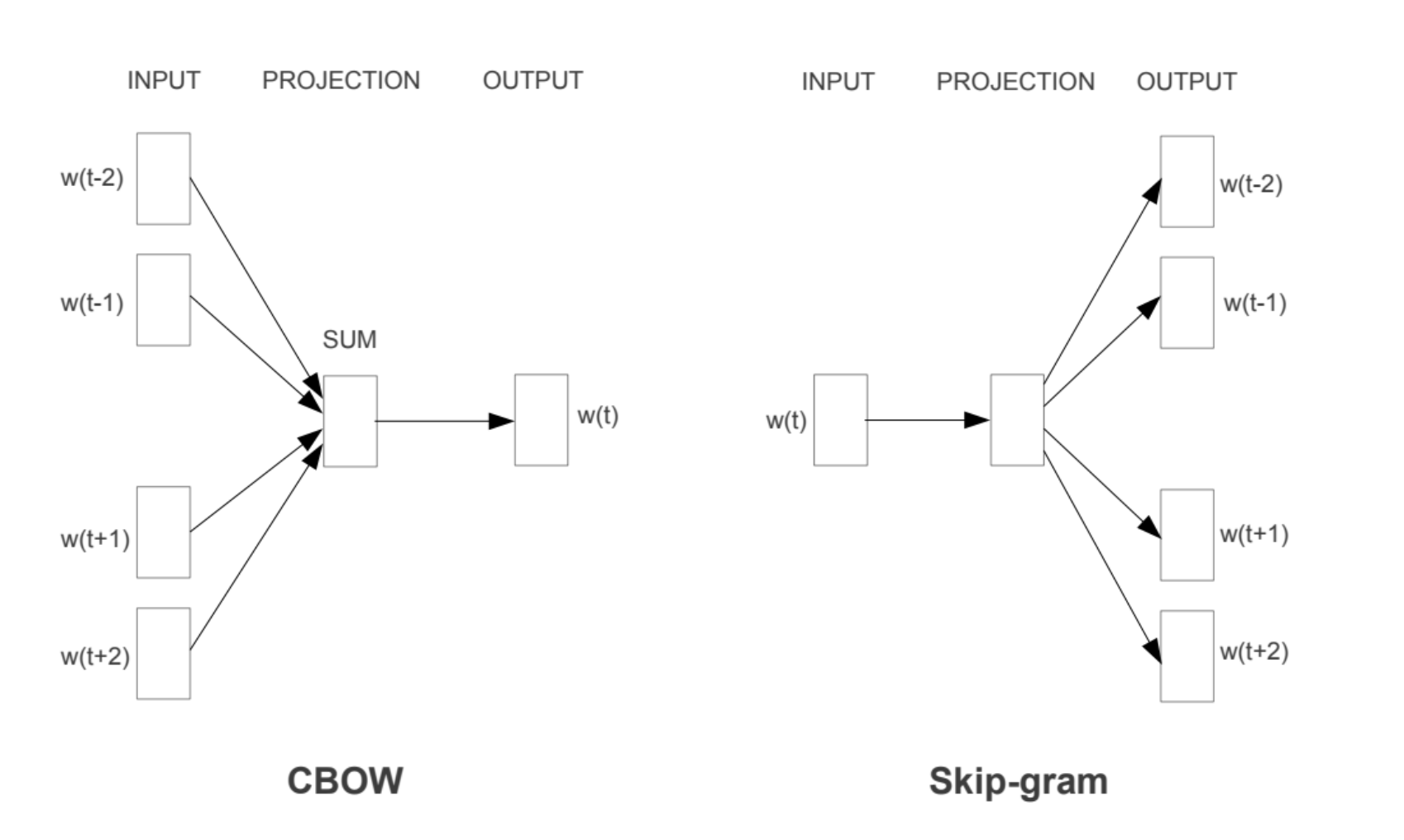 这两张图非常的简单,简单到初学者无法立刻get到Mikolov的意图。简单地说CBOW是使用中心单词的上下文信息(也就是距离这个单词最近的前后单词作为输入,优化向量使得这个中心单词出现的频率最高),而skip-gram反过来,利用中心单词推出上下文出现的概率。
这两张图非常的简单,简单到初学者无法立刻get到Mikolov的意图。简单地说CBOW是使用中心单词的上下文信息(也就是距离这个单词最近的前后单词作为输入,优化向量使得这个中心单词出现的频率最高),而skip-gram反过来,利用中心单词推出上下文出现的概率。
2. Skip-gram模型
为了进一步加快训练的速度,进一步发掘出词语之间的线性关系,本文对Skip-gram模型进行了扩展。目标函数如下没有什么变化:
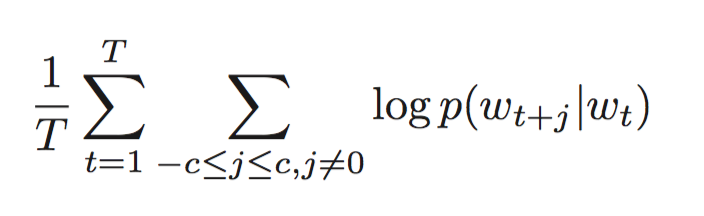 对于其中给定中心词,附近第j个词出现的概率由下式计算:
对于其中给定中心词,附近第j个词出现的概率由下式计算:
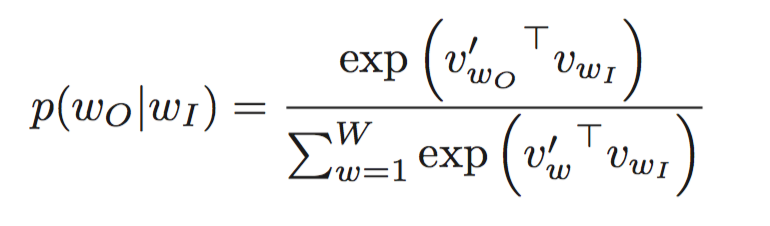 这里为什么使用向量的点乘呢?是因为余弦相似性cosine距离函数表达为
这里为什么使用向量的点乘呢?是因为余弦相似性cosine距离函数表达为
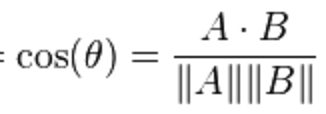 这里分母是定值,概率函数分子分母同乘它可以消去。
这里分母是定值,概率函数分子分母同乘它可以消去。
3. Hierarchical Softmax方法
为了让输出层的节点数量减少为log(W)的规模,采用层次的输出层结构,这个结构的好处是不用给每一个单词都准备两套词向量,而只需要计算和维护一套,然后对于输出层的每一个内部节点(不包括叶子节点,因为叶子节点使用的是输入的词向量)。需要优化的目标函数如下:
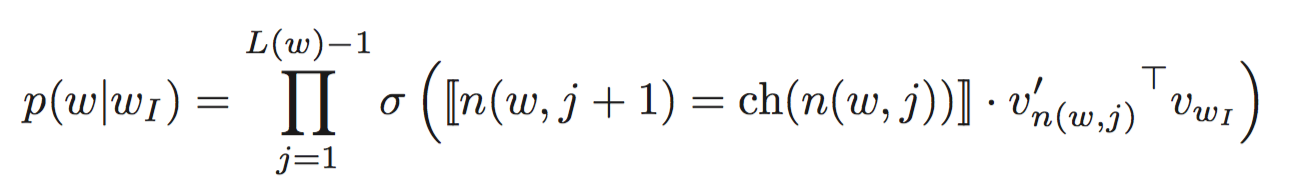 其中n(w,j)标识从根节点到单词w路径上的第j个节点,L(w)标识到单词w的路径长度,双线中括号含义是,如果内表达式为true结果是1,false结果为-1,至于等号的意思是,层次softmax可以看作是一个不断地二分过程,不是一般性的可以将左边孩子看做正,右边孩子看做负,相等就是同为正或者同为负。为了进一步加速训练,降低代价,在word2vec中二分数使用的是哈夫曼树。
其中n(w,j)标识从根节点到单词w路径上的第j个节点,L(w)标识到单词w的路径长度,双线中括号含义是,如果内表达式为true结果是1,false结果为-1,至于等号的意思是,层次softmax可以看作是一个不断地二分过程,不是一般性的可以将左边孩子看做正,右边孩子看做负,相等就是同为正或者同为负。为了进一步加速训练,降低代价,在word2vec中二分数使用的是哈夫曼树。
Negative Sampling负采样
除了层次softmax方法外,我们还可以使用Noise Contrastive Estimation (NCE)方法,NCE假设一个好的模型是能够使用logistic回归的方法将数据和噪声区分开来。在简化了的NCE的基础上,文章提出了负采样(NEG)的方法,目标函数是:
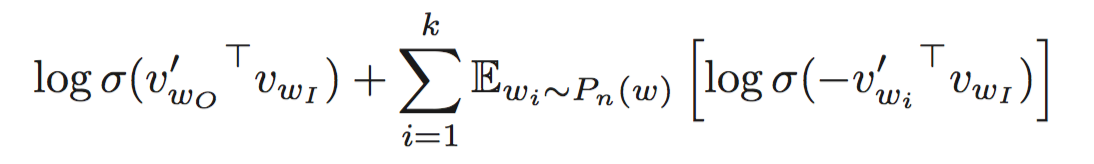 这个目标函数含义是最小化中心单词和上下文之间的距离的同时也能使得中心单词和从噪声分布中采样出来的噪声单词的距离很大。k是负采样的数量。文章中建议对于小训练集的情况下,k=5–20,对于大的训练集,k=2–5。
这个目标函数含义是最小化中心单词和上下文之间的距离的同时也能使得中心单词和从噪声分布中采样出来的噪声单词的距离很大。k是负采样的数量。文章中建议对于小训练集的情况下,k=5–20,对于大的训练集,k=2–5。
Pn(w) = U(w)3/4/Z会获得比较好的效果,这个分布简单说是单个词出现的频次的3/4次方除以所有词出现的次数的3/4次方的总和。
Subsampling of Frequent Words
对于很大的数据集,高频词给我们的带来的信息量远小于少见的词,我们需要进一步地减少高频词带来的计算cost。所使用的采样公式如下:
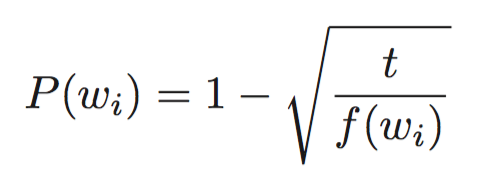 其中t是用户可以设置的阈值,f(w)是w出现的频率,如果概率超过阈值,那么就有被抛弃的可能性。
其中t是用户可以设置的阈值,f(w)是w出现的频率,如果概率超过阈值,那么就有被抛弃的可能性。
4. Learning Phrases
由于可能出现一些单词一块儿表示一个完整的含义,例如“New York Times”,所以需要找出短语,把他作为一个整体训练短语向量。找短语的原则是找出几个单词经常一块儿出现,并且和其他特定上下文一块儿出现的次数都远小于这几个单词。如果把所有的n-gram都作为短语放入skip-gram模型训练会导致内存消耗太大(现在的内存比13年要便宜不少,这还会是个问题吗?)。
对于每一对bigram计算分数作为系数构成一个系数矩阵:
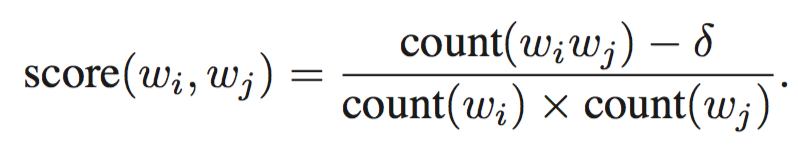 第一轮计算之后可以找出两个单词构成的短语,一般经过2-4轮之后可以找出大部分合理的短语。
第一轮计算之后可以找出两个单词构成的短语,一般经过2-4轮之后可以找出大部分合理的短语。
5. Additive Compositionality
skip-gram训练出来的词或者短语向量有个很有趣的特性那就是符合语义上的线性特征,比如“Russia”的向量和“river”的向量的代数和距离“Volga River”是最近的,原因很可能是这样的,softmax是关于词向量取log之后的函数,而词向量可以被看做是一个单词的上下文的概率分布,两个log函数之和是和两个单词的上下文概率分布乘积相关,所以可以看做是一个AND连接两个分布,表示有一些词或者短语作为上下文的一部分和这两个词都很接近。这样,向量和“Volga River”这个短语很近也就不奇怪了。(这样看起来Skip-gram model的可解释性也不错)。